
NVIDIA Container Runtime for Wind River Linux
Introduction
Training and using AI models are tasks that demand significant computational power. Current trends are pointing more to deep neural networks, which include thousands, if not millions of operations per iteration. In the past year, more and more researchers have sounded the alarm on the exploding costs of deep learning. The computing power needed to do AI is now rising seven times faster than ever before [1]. These new needs are making hardware companies create hardware accelerators like Neural processing units, CPUs, and GPUS.
Embedded systems are not an exception to this transformation. We see every day intelligent traffic lights, autonomous vehicles, intelligent IoT devices, and more. The current direction is to have accelerators inside these embedded devices, Systems OnChip mainly. Hardware developers have embedded small accelerators like GPUs, FPGAs, and more into SOCs, SOMs, and other systems. We call these modern systems: heterogeneous computing architectures.
The use of GPUs on Linux is not something new; we have been able to do so for many years. However, it would be great to accelerate the development and deployment of HPC applications. Containers enable portability, stability, and many other characteristics when deploying an application. For this reason, companies are investing so much in these technologies. For instance, NVIDIA recently started a project that enables CUDA on Docker [2]. One concern when dealing with containers is the loss of performance. However, when comparing the performance of the GPU with and without the containers environment, researchers found that no additional overhead is caused [3]. The consistency in the performance is one of the principal benefits of containers over virtual machines; accessing the GPU is done seamlessly as the kernel stays the constant.
NVIDIA-Docker on Yocto
Together with Matt Madison (Maintainer of meta-tegra layer), we created the required recipes to build and deploy NVIDIA-docker on Wind River Linux LTS 19 (Yocto 3.0 Zeus).[4]
In this tutorial, you will find how to enable NVIDIA-containers on a custom distribution of Linux and run a small test application that leverages the use of GPUs inside a container.
Description
To enable NVIDIA containers, Docker needs to have the nvidia-containers-runtime which is a modified version of runc that adds a custom pre-start hook to all containers. The nvidia-containers-runtime communicates docker using the library libnvidia-container, which automatically configures GNU/Linux containers leveraging NVIDIA hardware. This library relies on kernel primitives and is designed to be agnostic of the container runtime. All the effort to port these libraries and tools to Yocto was submitted to the community and now is part of the meta-tegra layer which is maintained by Matt Madison.
Note: this setup is based on Linux for Tegra and not the original Yocto Linux Kernel
Benefits, and Limitations
The main benefit of GPUs inside containers is the portability and stability in the environment at the time of deployment. Of course, the development also sees benefits in having this portable environment as developers can collaborate more efficiently. However, there are limitations due to the nature of the NVIDIA environment. Containers are heavy-weight because they are based in Linux4Tegra image that contains libraries required on runtime. On the other hand, because of redistribution limitations, some libraries are not included in the container. This requires runc to mount some property code libraries, losing portability in the process.
Prerequisites
You are required to download NVIDIA property code from their website. To do so, you will need to create an NVIDIA Developer Network account.
Go into https://developer.nvidia.com/embedded/downloads , download the NVIDIA SDK Manager, install it and download all the files for the Jetson board you own. All the effort to port these libraries and tools to Yocto was submited to the community and now is part of the meta-tegra layer which is maintained by Matt Madison. The required Jetpack version is 4.3
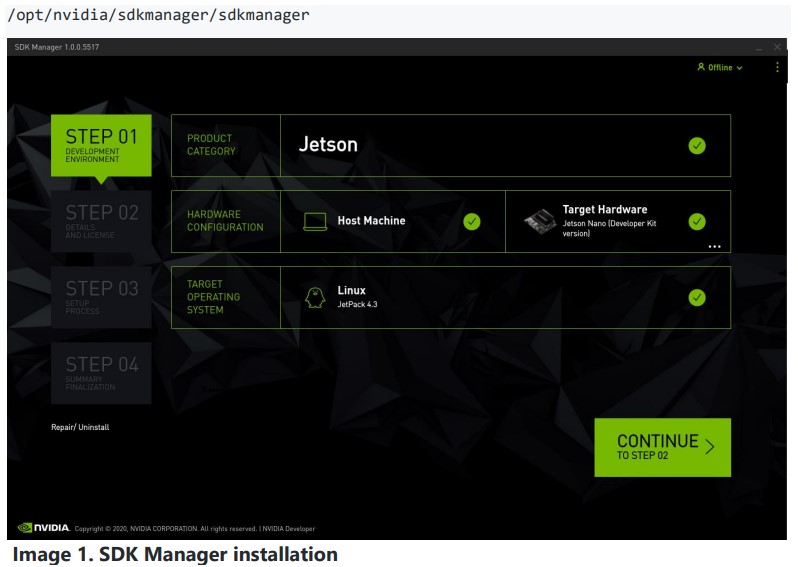
If you need to include TensorRT in your builds, you must create the subdirectory and move all of the TensorRT packages downloaded by the SDK Manager there.

Creating the project
![]()
Note: --distro wrlinux-graphics can be used for some applications that require x11.
Add meta-tegra layer
DISCAIMER: meta-tegra is a community maintained layer not supported by Wind River at the time of writing
![]()
Tested with: https://github.com/madisongh/metategra/commit/74de93aa9cdce39fe536ebe677ad33079adb0bf2

Configure the project
![]()
Set the machine to your Jetson Board
![]()
CUDA cannot be compiled with GCC versions higher than 7. Set GCC version to 7.%:
![]()
Set the IMAGE export type to tegraflash for ease of deployment.
![]()
Change the docker version, add nvidia-container-runtime.
![]()
Fix tini build error
![]()
Set NVIDIA download location

Add the Nvidia containers runtime, AI libraries and the AI libraries CSV files

Enable ldconfig required by the nvidia-container-runtime
![]()
Build the project
![]()
Burn the image into the SD card

Connect the Jetson Board to your computer using the microusb as shown in the image:

After connecting the board, run:
![]()
This command will create the file wrlinux-image-glibc-std.sdcard that contains the SD card image required to boot. Burn the Image to the SD Card:
![]()
Warning: substitute the of= device to the one that points to your sdcard Failure to do so can lead to unexpected erase of hard disks
Deploy the target
Boot up the board and find the ip address with the command ifconfig. Then, ssh into the machine and run docker:
![]()
Inside the container run:
![]()
References
• [1] K. Hao, “The computing power needed to train AI is now rising seven times faster than ever before”, MIT Technology Review, Nov. 2019. [Online]. Available: https://www.technologyreview.com/s/614700/the- computing- powerneeded- to- train-ai-is-now-rising-seven-times-faster-than-ever-before.
• [2] Nvidia, nvidia-docker, [Online; accessed 15. Mar. 2020], Feb. 2020. [Online]. Available:https://github.com/NVIDIA/nvidia-docker.
• [3] L. Benedicic and M. Gila, “Accessing gpus from containers in hpc”, 2016. [Online]. Available: http://sc16.supercomputing.org/scarchive/tech_poster/poster_files/post187s2-file3.pdf.
• [4] M. Madison, Container runtime for master, [Online; accessed 30. Mar. 2020], Mar. 2020. [Online]. Available:https://github.com/madisongh/metategra/pull/266
Wind River Blog
The Wind River Blog is made up of a variety of voices: executives, technologists and industry enthusiasts. We hope to foster conversations and encourage the sharing of insights regarding the evolving landscape of intelligent, connected systems with our ecosystem of customers, partners and colleagues.